It seems pretty surreal going through old lab notes again. It’s like a time capsule – an opportunity to laugh at your previous stupid self and your desperate attempts at trying to rectify that situation. My previous post on GDB’s fast tracepoints and their clever use of jump-pads longs for a more in-depth explanation on what goes on when you inject your own code in binaries.
Binary Instrumentation
The ability to inject code dynamically in a binary – either executing or on disk gives huge power to the developer. It basically eliminates the need of source code and re-compilation in most of the cases where you want to have your own small code run in a function and which may change the flow of program. For example, a tiny tracer that counts the number of time a certain variable was assigned a value of 42 in a target function. Through binary instrumentation, it becomes easy to insert such tiny code snippets for inexpensive tracing even in production system and then safely remove them once we are done – making sure that the overhead of static tracepoints is avoided as well. Though a very common task in security domain, binary instrumentation also forms a basis for debuggers and tracing tools. I think one of the most interesting study material to read from an academic perspective is Nethercote’s PhD Thesis. Through this, I learnt about the magic of Valgrind (screams for a separate blog post), the techniques beyond breakpoints and trampolines. In reality, most of us may not usually look beyond ptrace() when we hear about playing with code instrumentation. GDB’s backbone and some of my early experiments for binary fun have been with ptrace() only. While Eli Bendersky explains some of the debugger magic and the role of ptrace() in sufficient detail, I explore more on what happens when the code is injected and it modifies the process while it executes.
Primer
The techniques for binary instrumentation are numerous. The base of all the approaches is the ability to halt the process,identify an instrumentation point (a function, an offset from function start, an address etc.), modify its memory at that point, execute code and rewrite/restore registers. For on-disk dynamic instrumentation, the ability to load the binary, parse, disassemble and patch it with instrumentation code is required. There are then multiple ways to insert/patch the binary. In all these ways, there is always a tradeoff between overhead (size and the added time due to extra code added), control over the binary (how much and where can we modify) and robustness (what if the added code makes the actual execution unreliable – for example, loops etc.). From what I have understood from my notes, I basically classify ways to go about code patching. There may be more crazy ones (such as those used in viruses) but for tracing/debugging tools most of them are as follows :
- TRAP Based : I already discussed this in the last post with GDB’s normal tracepoints. Such a technique is also used in older non-optimized Kprobes. An exception causing instruction (such as int 3) is inserted at the desired point and its handler calls the code which you want to execute. Pretty standard stuff.
- JIT Recompilatin Based : This is something more interesting and is used by Valgrind. The binary is first disassembled, and converted to an intermediate representation (IR). Then IR is instrumented with the analysis code from the desired Valgrind tool (such as memcheck). The code is recompiled, stored in a code-cache and executed on a ‘synthetic CPU’. This is like JIT compilation but applied to analysis tools. The control over the information that can be gathered in such cases is very high, but so is the overhead (can go from 4x-50x slower in various cases).
- Trampoline Based : Boing! Basically, we just patch the location with a jump to a jump-pad or trampoline (different name for same thing). This trampoline can execute the displaced instructions and then prepare another jump to the instrumented code and then back to the actual code. This out-of-line execution maintains sufficient speed, reduced overhead as no TRAP, context switch or handler call is involved. Many binary instrumentation frameworks such as Dyninst are built upon this. We will explain this one in further detail.
Dyninst’s Trampoline
Dyninst’s userspace-only trampoline approach is quite robust and fast. It has been used in performance analysis tools such as SystemTap, Vampir and Tau and hence a candidate for my scrutiny. To get a feel of what happens under the hood, lets have a look at what Dyninst does to our code when it patches it.
Dyninst provides some really easy to use APIs to do the heavy lifting for you. Most of them are very well documented as well. Dyninst introduces the concept of mutator which is the program that is supposed to modify the target or mutatee. This mutatee can either be a running application or a binary residing on disk. The process attaching or creating a new target process allows the mutator to control the execution of the mutatee. This can be achieved by either processCreate() or processAttach(). The mutator then gets the program image using the object, which is a static representation of the mutatee. Using the program image, the mutator can identify all possible instrumentation points
in the mutatee. The next step is creating a snippet (or the code you want to insert) for insertion at the identified point. The mutator can then create a snippet, to be inserted into the mutatee. Building small snippets can be trivial. For example, small snippets can be defined using the BPatch arithExpr and BPatch varExp types. Here is a small sample. The snippet is compiled into machine language and copied into the application’s address space. This is easier said than done though. For now, we just care about how the snippet affects our target process.
Program Execution flow
The Dyninst API inserts this compiled snippet at the instrumentation points. Underneath is the familiar ptrace()technique of pausing and poking memory. The instruction at the instrumentation point is replaced by a jump to a base trampoline. The base trampoline then jumps to a mini-trampoline that starts by saving any registers that will be modified. Next, the instrumentation is executed. The mini-trampoline then restores the necessary registers, and jumps back to the base trampoline. Finally, the base trampoline executes the replaced instruction and jumps back to the instruction after the instrumentation point. Here is a relevant figure taken from this paper :
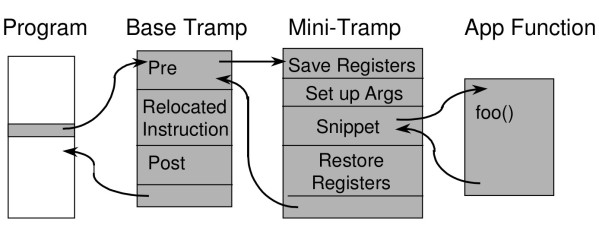

As part of some trials, I took a tiny piece of code and inserted a snippet at the end of the function foo(). Dyninst changed it to the following :

Hmm.. interesting. So the trampoline starts at 0x10000 (relative to PC). Our instrumentation point was intended to be function exit. It means Dyninst just replaces the whole function in this case. Probably it is safer this way rather than replacing a single or a small set of instructions mid function. Dynisnt’s API check for many other things when building the snippet. For example, we need to see if the snippet contains code that recursively calls itself causing the target program to stop going further. More like a verifier of code being inserted (similar to eBPF’s verifier in Linux kernel which checks for loops etc before allowing the eBPF bytecode execution). So what is the trampoline doing? I used GDB to hook onto what is going on and here is a reconstruction of the flow :

Clearly, the first thing the trampoline does is execute the remaining function out of line, but before returning, it start preparing the snippet’s execution. The snippet was a pre-compiled LTTng tracepoint (this is a story for another day perhaps) but you don’t have to bother much. Just think of it as a function call to my own function from within the target process. First the stack is grown and the machine registers are pushed on to the stack so that we can return to the state where we were after we have executed the instrumented code. Then it is grown further for snippet’s use. Next, the snippet gets executed (the gray box) and the stack is shrunk back again to the same amount. The registers pushed on the stack are restored along with the original stack pointer and we return as if nothing happened. There is no interrupt, no context-switch, no lengthy diversions. Just simple userspace code 
So now we know! You can use Dyninst and other such frameworks like DynamoRIO or PIN to build your own tools for tracing and debugging. Playing with such tools can be insane fun as well. If you have any great ideas or want me to add something in this post, leave a comment!
Source: https://suchakra.wordpress.com/2016/07/03/unravelling-code-injection-in-binaries/
原创文章,作者:江海志,如若转载,请注明出处:https://jianghaizhi.com/bckf/1241.html