
首先来一句概括的总论:进程和线程都是一个时间段的描述,是CPU工作时间段的描述。是运行中的程序指令的一种描述,这需要与程序中的代码区别开来。
另外注意这里我说的进程线程概念,和编程语言中的API接口对应的进程/线程是有差异的。
下面细说背景:
CPU+RAM+各种资源(比如显卡,光驱,键盘,GPS, 等等外设)构成我们的电脑,但是电脑的运行,实际就是CPU和相关寄存器以及RAM之间的事情。
一个最最基础的事实:CPU太快,太快,太快了,寄存器仅仅能够追的上他的脚步,RAM和别的挂在各总线上的设备则难以望其项背。那当多个任务要执行的时候怎么办呢?轮流着来?或者谁优先级高谁来?不管怎么样的策略,一句话就是在CPU看来就是轮流着来。而且因为速度差异,CPU实际的执行时间和等待执行的时间是数量级的差异。比如工作1秒钟,休息一个月。所以多个任务,轮流着来,让CPU不那么无聊,给流逝的时间增加再多一点点的意义。这些任务,在外在表现上就仿佛是同时在执行。
一个必须知道的事实:执行一段程序代码,实现一个功能的过程之前 ,当得到CPU的时候,相关的资源必须也已经就位,就是万事俱备只欠CPU这个东风。所有这些任务都处于就绪队列,然后由操作系统的调度算法,选出某个任务,让CPU来执行。然后就是PC指针指向该任务的代码开始,由CPU开始取指令,然后执行。
这里要引入一个概念:除了CPU以外所有的执行环境,主要是寄存器的一些内容,就构成了的进程的上下文环境。进程的上下文是进程执行的环境。当这个程序执行完了,或者分配给他的CPU时间片用完了,那它就要被切换出去,等待下一次CPU的临幸。在被切换出去做的主要工作就是保存程序上下文,因为这个是下次他被CPU临幸的运行环境,必须保存。
串联起来的事实:前面讲过在CPU看来所有的任务都是一个一个的轮流执行的,具体的轮流方法就是:先加载进程A的上下文,然后开始执行A,保存进程A的上下文,调入下一个要执行的进程B的进程上下文,然后开始执行B,保存进程B的上下文。。。。
========= 重要的东西出现了========
进程和线程就是这样的背景出来的,两个名词不过是对应的CPU时间段的描述,名词就是这样的功能。
- 进程就是上下文切换之间的程序执行的部分。是运行中的程序的描述,也是对应于该段CPU执行时间的描述。
- 在软件编码方面,我们说的进程,其实是稍不同的,编程语言中创建的进程是一个无限loop,对应的是tcb块。这个是操作系统进行调度的单位。所以和上面的cpu执行时间段还是不同的。
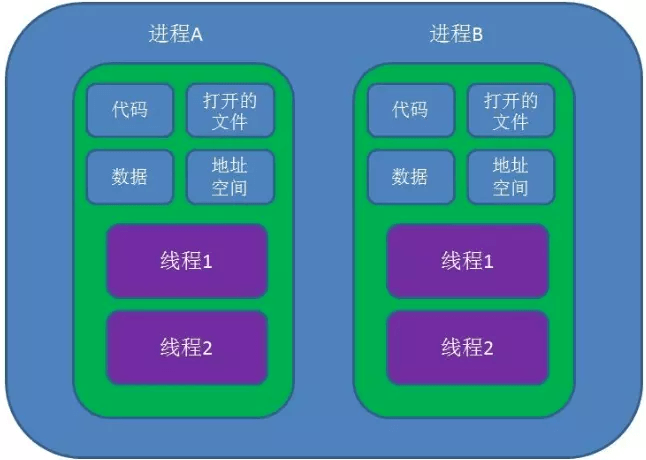
- 进程,与之相关的东东有寻址空间,寄存器组,堆栈空间等。即不同的进程,这些东东都不同,从而能相互区别。
线程是什么呢?
进程的颗粒度太大,每次的执行都要进行进程上下文的切换。如果我们把进程比喻为一个运行在电脑上的软件,那么一个软件的执行不可能是一条逻辑执行的,必定有多个分支和多个程序段,就好比要实现程序A,实际分成 a,b,c等多个块组合而成。那么这里具体的执行就可能变成:
程序A得到CPU =》CPU加载上下文,开始执行程序A的a小段,然后执行A的b小段,然后再执行A的c小段,最后CPU保存A的上下文。
这里a,b,c的执行是共享了A进程的上下文,CPU在执行的时候仅仅切换线程的上下文,而没有进行进程上下文切换的。进程的上下文切换的时间开销是远远大于线程上下文时间的开销。这样就让CPU的有效使用率得到提高。这里的a,b,c就是线程,也就是说线程是共享了进程的上下文环境,的更为细小的CPU时间段。线程主要共享的是进程的地址空间。
到此全文结束,再一个总结:
进程和线程都是一个时间段的描述,是CPU工作时间段的描述,不过是颗粒大小不同。
注意这里描述的进程线程概念和实际代码中所说的进程线程是有区别的。编程语言中的定义方式仅仅是语言的实现方式,是对进程线程概念的物化。
原创文章,作者:江海志,如若转载,请注明出处:https://jianghaizhi.com/research/systemsecurity/1747.html