-
Ubuntu 64基本环境配置
-
安装JDK,下载jdk-8u45-linux-x64.tar.gz,解压到/opt/jdk1.8.0_45
-
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
-
安装scala,下载scala-2.11.6.tgz,解压到/opt/scala-2.11.6
下地地址: http://www.scala-lang.org/
-
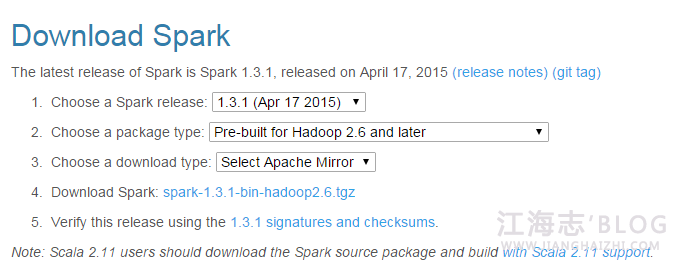
安装Spark,下载spark-1.3.1-bin-hadoop2.6.tgz,解压到/opt/spark-hadoop
下载地址:http://spark.apache.org/downloads.html,
配置环境变量,编辑/etc/profile,执行以下命令
python@ubuntu :~$ sudo gedit /etc/profile
在文件最增加:
#Seeting JDK JDK环境变量
export JAVA_HOME=/opt/jdk1.8.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#Seeting Scala Scala环境变量
export SCALA_HOME=/opt/scala-2.11.6
export PATH=${SCALA_HOME}/bin:$PATH
#setting Spark Spark环境变量
export SPARK_HOME=/opt/spark-hadoop/
#PythonPath 将Spark中的pySpark模块增加的Python环境中
export PYTHONPATH=/opt/spark-hadoop/python
重启电脑,使/etc/profile永久生效,临时生效,打开命令窗口,执行 source /etc/profile 在当前窗口生效
-
测试安装结果
-
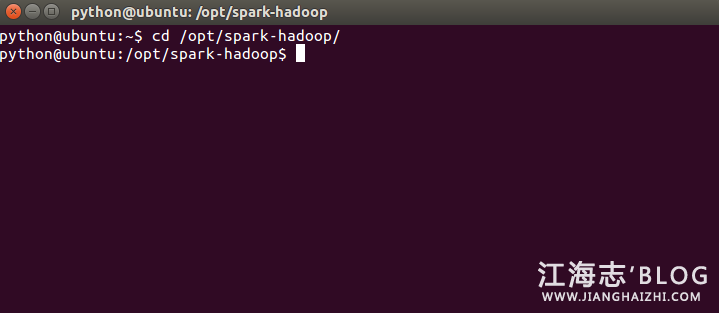
打开命令窗口,切换到Spark根目录
-
-
执行 ./bin/spark-shell,打开Scala到Spark的连接窗口
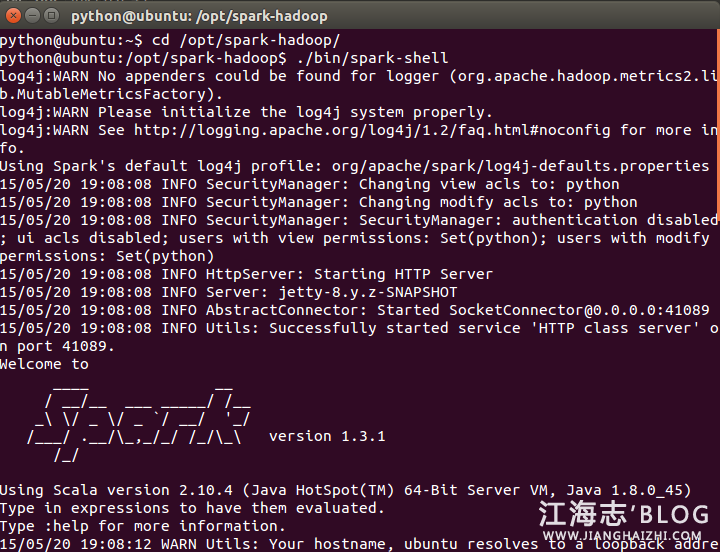
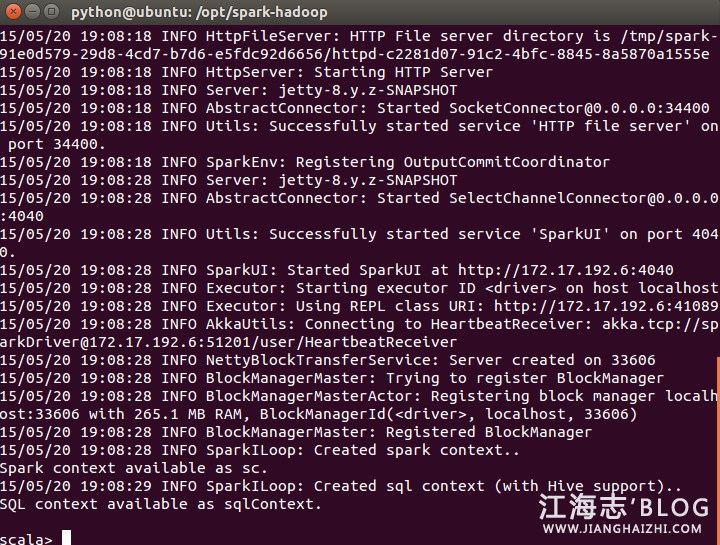
启动过程中无错误信息,出现scala>,启动成功
-
执行./bin/pyspark ,打开Python到Spark的连接窗口
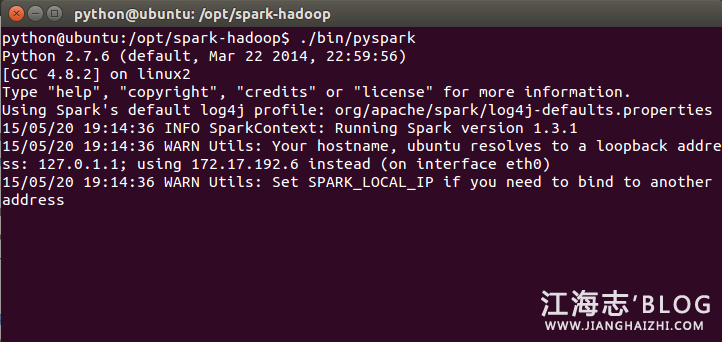
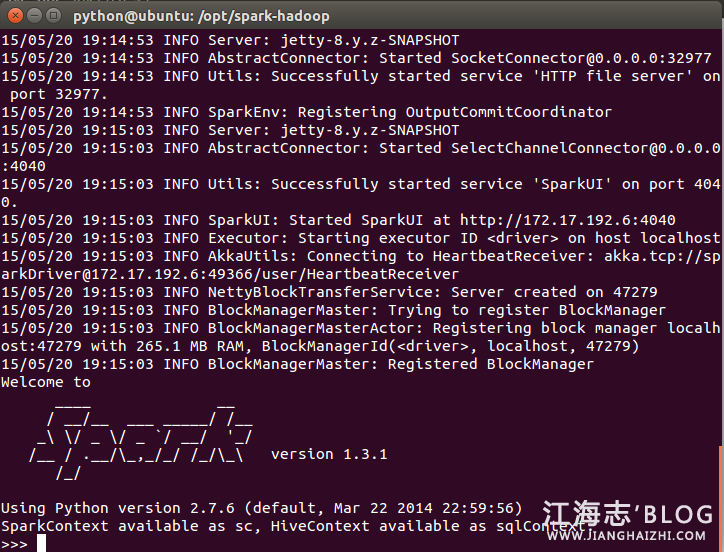
启动过程中无错误,在出现如上所示时,启动成功。
-
通过浏览器访问:出现如下页面
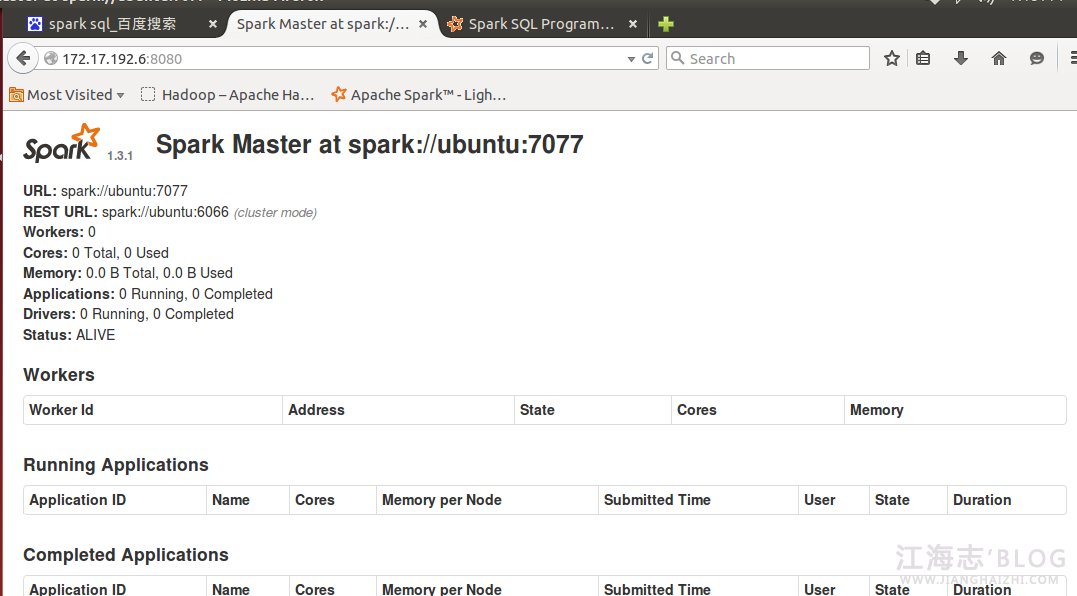
测试SPark可用
转载请注明:江海志の博客 » Ubuntu下基于hadoop安装Spark开发环境